
残差接続の本質——恒等写像が深層学習を変えた理由
2015年のResNet論文(He et al.)が提案した残差接続(Residual Connection)は、深層ニューラルネットワーク学習の根本的な問題を解決した。問題の本質は「勾配消失」だが、残差接続が効く本当の理由はそれだけではない。
残差ブロックの式はシンプルだ。x_{l+1} = x_l + F(x_l) という形で、入力 x_l がそのまま出力に加算される。この「そのまま加算」が鍵で、恒等写像(Identity Mapping)が常に利用可能なパスとして確保される。ネットワークが何も学べなかった最悪の場合でも、入力がそのまま次の層に流れるため、学習開始時のグラデーションが非常に安定する。ResNetの深さが50層・101層・152層と積み上がっても学習できた理由がここにある。
残差接続を混合行列 W として定式化すると、単純な残差接続は実質的に W = I(単位行列)に等しい。各行の和が1、各列の和が1という性質——これがHyper-Connections研究の出発点になる。
Hyper-Connectionsの「設計意図」と「構造的欠陥」
Hyper-Connections(HC)は、残差接続をより柔軟にしようとした試みだ。単一の恒等パスではなく、複数の異なる深さのレイヤー出力を重み付きで混合する「深さ方向の混合」を実現する。具体的には、スカラーの重み1の代わりに混合行列 M ∈ ℝ^{n×n} を使い、複数層の入力の線形結合を学習させる設計だ。
直感的には合理的に見える。浅い層と深い層の情報を適切な比率で混合できれば、残差接続の「等重みで加算」よりも表現力が高まるはずだ。しかし、この設計には致命的な欠陥が潜んでいた。
学習中に混合行列 M の行和と列和が保証されなくなる問題だ。残差接続が恒等写像を保証できた理由は、M = I(各行の和が1、対角成分が1)という構造的制約があるからだった。HCではこの制約が消え、M の成分が任意の値を取れるため、学習が進むにつれて「恒等写像としての性質」が失われていく。その結果、損失が発散しやすくなる、あるいは収束が遅くなる問題が生じた。恒等パスを「保証する仕組み」なしに自由度を与えすぎたのだ。

Birkhoff多面体制約——二重確率行列が安定性を回復する数学的理由
mHC(Manifold-Constrained Hyper-Connections)の核心的なアイデアは、混合行列 M を「Birkhoff多面体」(B_n)と呼ばれる凸多面体に制約することだ。
Birkhoff多面体は、n×n の二重確率行列(doubly stochastic matrix)全体が作る凸集合として定義される。二重確率行列とは、全ての成分が非負で、各行の和が1かつ各列の和が1である行列のことだ。最も単純な例は単位行列 I_n だが、任意の置換行列(各行・各列に1が1つある行列)もBirkhoff多面体の頂点になる。バーコフ-フォン・ノイマン定理によれば、二重確率行列は全ての置換行列の凸結合として表現できる。
なぜ二重確率行列への制約が恒等写像特性を回復するのか。行和と列和がそれぞれ1に保たれることで、混合行列 M が情報を「増幅・消滅」させることなく「再分配」するだけになる。M x を計算したとき、各成分の重み付き平均が常に正規化されており、入力の総和が保存される。これが残差接続と同じ「情報フローの安定性」を保証する仕組みだ。単位行列 I は二重確率行列の一種であるため、学習開始時の挙動が純粋な残差接続と等価になる、という性質も重要だ。
Sinkhorn-Knoppアルゴリズムによる制約投影の実装
数学的な動機は明確だが、実装上の課題が残る。学習中に行列の勾配更新を行うたびに「二重確率行列の制約を満たしているか」を確認し、違反していれば投影操作が必要になる。この投影をいかに効率よく行うかがmHCの実装の鍵だ。
DeepSeekが採用したのはSinkhorn-Knoppアルゴリズムだ。このアルゴリズムは1967年に提案された古典的な手法で、任意の非負行列を二重確率行列に収束させる反復正規化アルゴリズムとして知られる。手順は極めてシンプルだ。①各行を行の和で正規化(行確率行列化)、②各列を列の和で正規化(列確率行列化)、という2ステップを交互に繰り返す。この反復が収束したとき、行列は二重確率行列になっている。
Sinkhorn-Knoppの実装上の魅力は、各イテレーションがO(n²)の行列演算のみで完結し、GPU上での並列化が容易な点だ。実験では数イテレーションで十分な精度に収束することが確認されており、計算オーバーヘッドを最小限に抑えつつBirkhoff多面体への投影を実現できる。論文が報告する6-7%のオーバーヘッドという数値は、Sinkhorn-Knopp収束の速さに起因する。
実験結果と既存手法との位置関係——0.021改善が示すもの
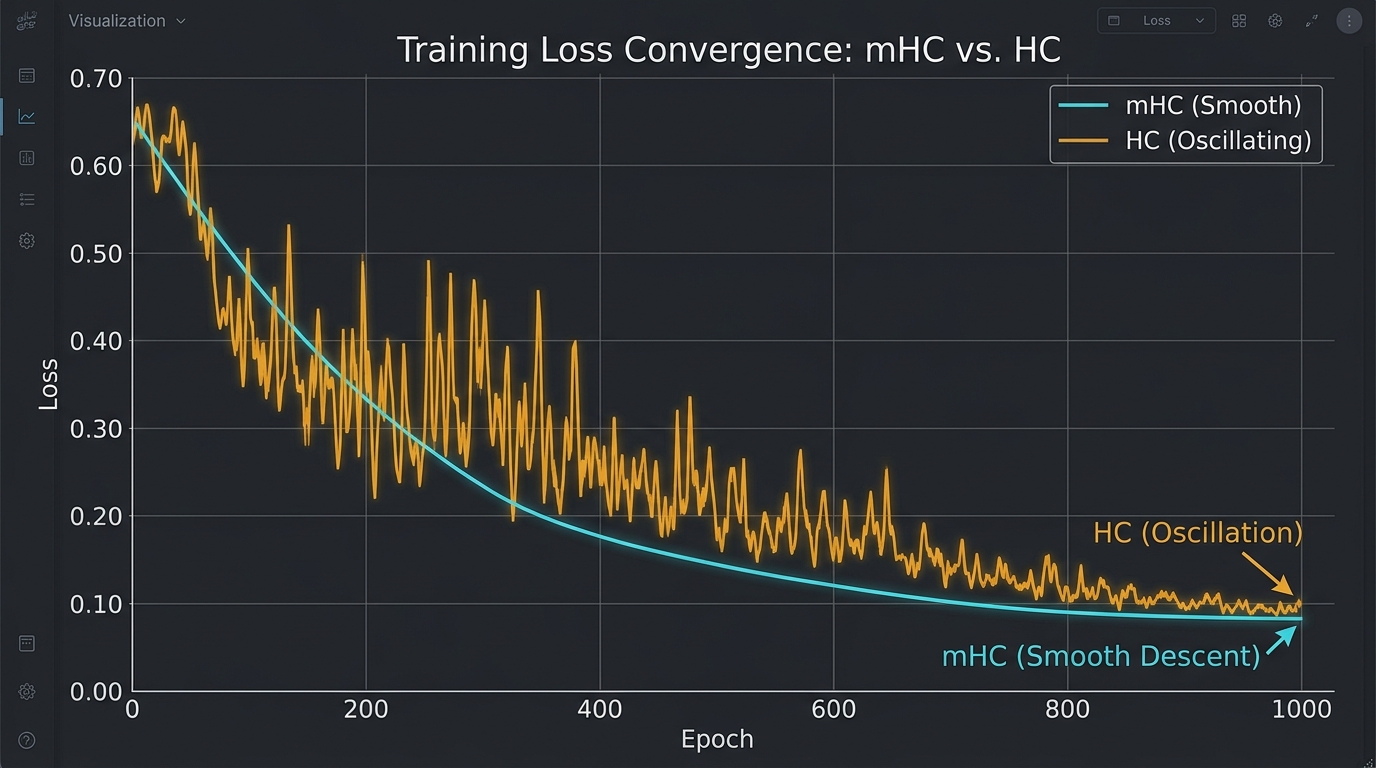
DeepSeekの報告によれば、mHCを適用したモデルは通常の残差接続ベースラインに対して損失値が0.021改善した。Transformerの事前学習における0.021の損失改善は、絶対値としては小さく見えるが、対数損失のスケールでは相当の品質差に相当する。同等の品質改善を学習トークン数の増加で達成しようとすると、大規模モデルでは追加の計算コストが桁違いになる場合がある。
計算オーバーヘッドは6-7%に留まる。MegaTrain(Deep Signalで既報)が「ホストメモリへのオフロードでVRAM制約を外す」というトレーニング効率化を追求したのとは異なり、mHCはアーキテクチャレベルの改善として損失の質そのものを上げるアプローチだ。前者が「同じモデルをより少ないリソースで動かす」効率化であるのに対し、後者は「同じリソースでより賢いモデルを作る」品質改善という相補的な関係にある。どちらも「大規模Transformerの学習コストをどう正当化するか」という問いへの異なる回答だ。
DeepSeek設計哲学の系譜——「制約の数学化」という一貫したアプローチ
mHCはDeepSeekの設計思想の文脈で見ると、その位置づけがよりクリアになる。DeepSeekはMLA(Multi-Head Latent Attention)とMoE(Mixture-of-Experts)の独自実装でDeepSeek-V2/V3を構成し、アテンション計算とFeed-Forward層の両方でアーキテクチャレベルの革新を施した。mHCはそこに「残差接続の数学的制約」という第三の軸を加える。
3つのイノベーションに共通する設計哲学は「数学的な構造制約による性能保証」だ。MLAは低ランク射影によるKVキャッシュの削減、MoEは疎活性化による計算効率の向上、mHCはBirkhoff多面体制約による学習安定性の保証。いずれも「アドホックな経験的調整」ではなく「理論的に正当化できる制約」を先に設計し、その上で実装を最適化するアプローチだ。
S2D2(Deep Signalで既報)が拡散LLMの推論高速化において「同一モデル内の異なるステップ数で自己推測デコードを実現する」という構造的制約を活用したのと同様に、mHCも「混合行列が二重確率行列の多様体上に留まる」という制約を出発点にしている。アーキテクチャ研究における「制約の数学化」という潮流が、DeepSeekと最先端の推論効率化研究の両方に貫かれている点は注目に値する。残差接続の発明から10年を経て、その制約の意味を数学的に再定式化し直す研究が出てきていることは、深層学習アーキテクチャ研究の成熟を示す動きとして筆者には映る。


