
「S2D2: Fast Decoding for Diffusion LLMs via Training-Free Self-Speculation」は、近年注目を集めている拡散ベースの言語モデル(Diffusion LLM)の推論速度を大幅に改善する手法を提案している。追加のトレーニングを必要とせず、既存の拡散LLMに適用できる実用的な高速化手法だ。
拡散LLMとは何か
従来の言語モデル(GPT、Claude等)はautoregressiveと呼ばれる手法で、トークンを左から右へ一つずつ順番に生成する。これに対し、拡散LLMはガウシアンノイズから始めて反復的なノイズ除去プロセスで全トークンを同時に生成する別のパラダイムだ。

拡散モデルは画像生成(DALL-E、Stable Diffusion)で革命を起こした手法であり、これを言語生成に応用しようという試みがMDLM、MDLM-Pro、LFMなどの研究で進んでいる。拡散LLMの理論的な強みは、文章全体の整合性を保ちながら生成できる可能性があること、そして双方向的な文脈理解が自然にできることだ。
拡散LLMのボトルネック:遅い推論
拡散LLMの実用化における最大の障壁は推論速度だ。Autoregressive LLMが一度のフォワードパスで一トークンを生成するのに対し、拡散LLMは多数のデノイジングステップを繰り返す必要があり、同じ長さのテキストを生成するのに数十倍の計算コストがかかる場合がある。
この問題に対するこれまでのアプローチは、デノイジングステップ数を削減する方法(品質が低下するリスクがある)や、より高速なサンプリングスケジュールを学習する方法(追加トレーニングが必要)が中心だった。
S2D2のアプローチ
S2D2(Self-Speculative Decoding for Diffusion)は、LLMの世界で研究されてきた「Speculative Decoding(推測的デコード)」のアイデアを拡散LLMに応用する。
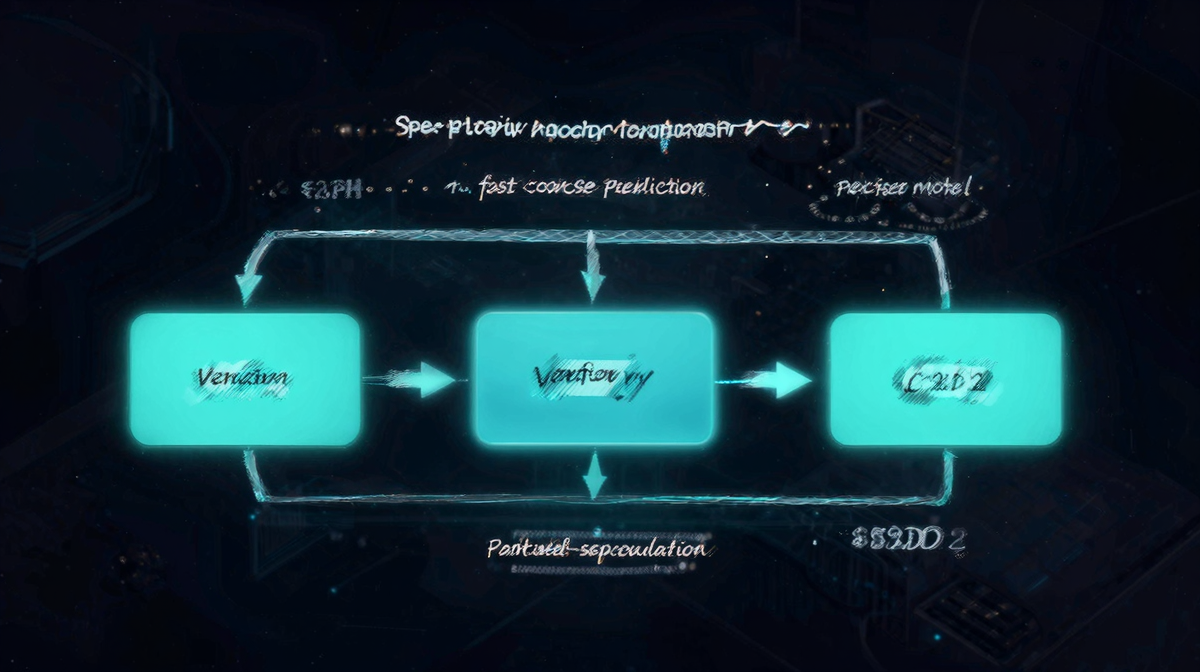
Speculative Decodingの基本アイデアは、「小さくて速いモデル(ドラフトモデル)が生成した候補を、大きくて遅いモデル(ベリファイモデル)が並行して検証・採用・棄却する」というものだ。S2D2はこれを「同一モデルの異なるデノイジングステップ数」で実現する。少ないステップ数での「粗い」推測を多いステップ数での「精密な」検証が補正することで、品質を保ちながら速度を向上させる。
追加トレーニング不要の重要性
S2D2の最大のセールスポイントは「Training-Free」、すなわち追加のトレーニングが不要な点だ。既存の拡散LLMに後付けで適用できるため、MDLMやLFMなど現在研究されているモデルへの即座の適用が可能。実験では複数のベースラインと比較して推論速度が大幅に向上し、品質の低下も最小限に抑えられたことが示されている。

拡散LLMが実用的なパフォーマンスを達成すれば、autoregressive LLMとは異なる特性(非自己回帰的な生成、双方向文脈理解)を持つ新しいクラスのAIシステムが生まれる可能性がある。S2D2はその実現への重要な一歩だ。
推測デコードの横展開:HeiSDとの共鳴
S2D2が提唱する「自己推測デコード」のアイデアは、同時期に発表されたロボット制御領域の研究とも響き合う。HeiSD(arXiv:2603.17573、Deep Signal既報)は、VLAモデルのロボット制御においてハイブリッド推測デコードと運動学的知識を組み合わせ、推論を2.8倍高速化することに成功している。HeiSDが「速い粗い予測」と「遅い精密な検証」を組み合わせるアーキテクチャは、S2D2の少ないステップ数の粗い推測を多いステップ数が補正するメカニズムと本質的に同じ思想を持つ。推測デコードという手法が、言語生成・拡散生成・ロボット制御という異なる領域で同時多発的に「高速化のデファクト手法」になりつつあることは注目に値する。
R-C2との対比:「学習なし改善」という新潮流
R-C2(Deep Signal既報)もまた、追加の学習データなしにVLMのマルチモーダル推論を改善するフレームワークを提案している。S2D2が「速度」を、R-C2が「推論精度」というそれぞれ異なるボトルネックに取り組みながら、どちらも「既存モデルを追加トレーニングなしに改善する」という共通の制約を戦略的強みに変えている。モデルの訓練コストが増大し続ける中、training-freeのアプローチは商用展開の観点からも魅力的な選択肢であり、この方向性の研究は今後も増加すると予測される。


