
Meta Superintelligence Labが2026年4月に公開したMuse Sparkは、マルチモーダル推論の問題に対して特定のアーキテクチャ上の賭けをしている。画像・テキスト・音声といった異なるモダリティを、後処理で統合するのではなく、Transformer内部の表現空間レベルで統一するという選択だ。この記事では、Muse Sparkの公開情報に基づいて、その設計の核心にある3つのコンポーネント——Unified Modality Tokens(UMT)、Cross-Modal Attention Fusion(CMAF)、そして思考圧縮——を解剖する。
Unified Modality Tokens——全モダリティを共有ベクトル空間に投射する設計
従来のマルチモーダルモデルの多くは、モダリティごとに専用のエンコーダを持ち、それらの出力を後から連結するアーキテクチャを採用してきた。LLaVAやGPT-4Vがその典型で、視覚エンコーダの出力をプロジェクション層でテキスト埋め込み空間に変換してからLLMに渡す構造だ。
Muse SparkのUMTは、この分離構造を根本から見直す。テキスト・画像・音声・動画フレームを問わず、全入力を学習された単一のトークン化機構で共通のベクトル空間に変換する。テキストはBPEトークナイザーの代わりに、画像パッチや音声スペクトログラムと同一の埋め込み次元に直接投射される。「犬の画像」と「犬というテキスト」が事前学習段階から同じトークン空間の近傍に配置されるよう最適化が進む設計だ。
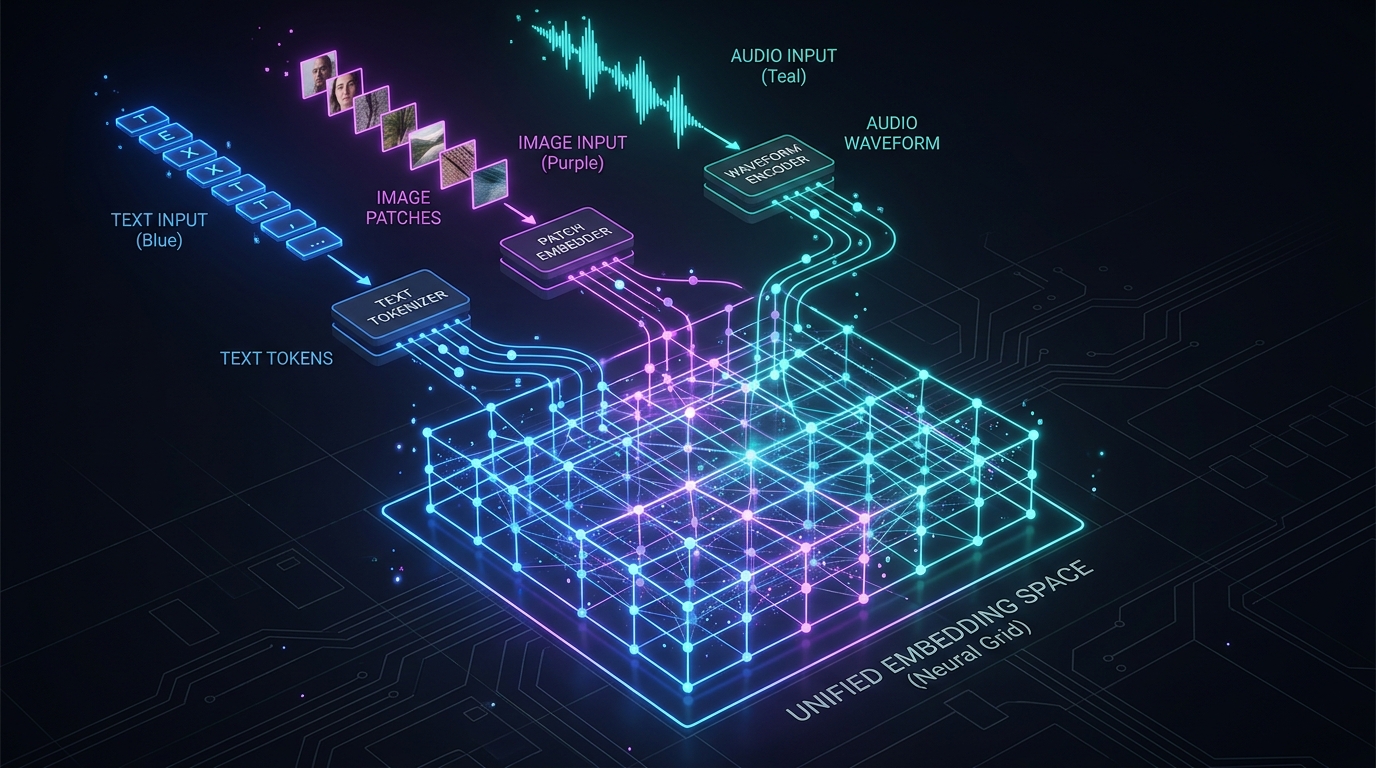
この設計の理論的な利点は、モダリティ間の意味的関係が学習段階から1つの表現空間で扱われることにある。プロジェクション層を経由する間接的な変換ではなく、異なる感覚入力の意味的距離が直接最適化される。筆者の読みでは、これはRAGでの検索精度を改善するアプローチに近い発想——多様な情報源を共通の埋め込み空間で扱うことで検索が機能する——をモデル内部に内在化したものと解釈できる。
ただし、UMTが有効に機能するかどうかは事前学習データの構成に大きく依存する。テキスト単体のデータに比べて、画像・テキストや音声・テキストのペアデータは収集が難しく、データ量の非対称性がトークン空間の品質を左右する。MetaはInstagram・Facebook等の大規模マルチモーダルデータを保有しており、この点でUMTアーキテクチャとMetaのデータ資産には強い親和性がある。公開データのみで事前学習した競合モデルが同じアーキテクチャを採用しても同水準の性能を出せるかどうかは、評価が難しい。
Cross-Modal Attention Fusionの仕組み——ヘッドレベルで動的に切り替わる注意機構
UMTが表現空間の統一を担うのに対し、CMAFはTransformerの推論過程でモダリティ間の情報統合を制御する機構だ。標準的なMulti-Head Attentionでは全てのヘッドが入力シーケンス全体に等しくアクセスするが、CMAFはこの構造を拡張する。各アテンションヘッドが「モダリティ内注意(intra-modal attention)」と「モダリティ間注意(cross-modal attention)」を動的に切り替えるゲーティング機構を持つ。
具体的には、各アテンションヘッドにゲート重み g∈[0,1] が付与される。g が高いとき、そのヘッドはテキストトークン間だけの注意を計算する(言語的推論に特化)。g が低いとき、画像・音声トークンを含む全シーケンスへの注意を計算する(マルチモーダル統合)。この値は入力の内容に応じて動的に決定される——テキストのみの質問には言語ヘッドが支配的になり、「この画像に何が写っているか」のようなビジュアルクエリには視覚統合ヘッドが活性化する。

CMAFの設計が興味深いのは、推論コストの動的調整を可能にする点だ。テキストのみのタスクでは、クロスモーダルヘッドの計算がほぼ無効化されるため、テキスト専用モデルと同等の計算量で処理できる。マルチモーダルタスクでのみ追加コストが発生するという設計は、WhatsApp・Instagramという多様なクエリが混在する本番環境への展開を意識したものに見える。
ViT(Vision Transformer)では視覚処理専用の層が設計段階から固定されているが、CMAFでは各ヘッドが文脈に応じて役割を変える。この動的な役割分担は特定のモダリティへの過学習リスクを軽減し得るが、一方で学習時の安定性確保が難しいトレードオフがある。最適なゲート値分布がどのようなデータ分布から学習されるかは、詳細な技術論文の公開を待つ必要がある。
思考圧縮とマルチエージェントオーケストレーション——推論コストの再設計
大規模推論モデルの共通課題は、Chain-of-Thought(CoT)推論時の中間トークン数の膨張だ。複雑な数学問題や視覚的推論では、最終答えに辿り着くまでに数千トークンの思考過程が生成される。これはAPI利用コストを押し上げるだけでなく、コンテキスト長の制約にも引っかかる。
Muse Sparkの思考圧縮(Thought Compression)は、長い中間推論過程を「要約トークン」に凝縮しながら推論を進める技術だ。全ての思考ステップを明示的なトークンとして保持する代わりに、推論の要点だけを保持した圧縮表現を内部状態として利用する。公開された評価では、思考圧縮なしと比較して推論トークン数を平均37〜63%削減しながら、ベンチマークスコアの低下を5%以内に抑えたとされている。
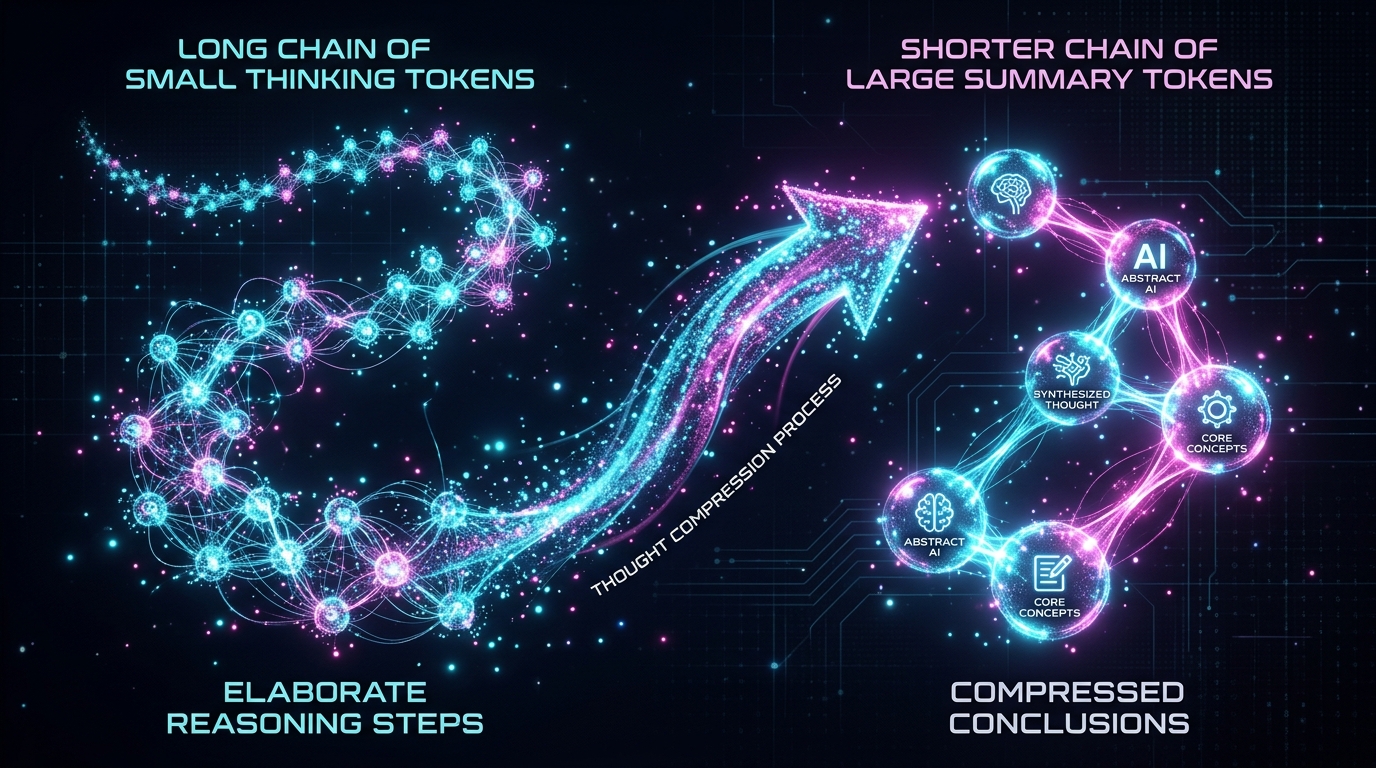
もう一つの特徴がマルチエージェントオーケストレーションだ。Muse Sparkは単一モデルとして動作するだけでなく、複数の特化エージェント(視覚理解・言語推論・コード生成等)を並列起動し、それぞれの部分解を集約する仕組みを持つ。並列推論の最終集約にはCoT結果のクロスチェックを含む投票メカニズムが使われており、単一パスの推論より頑健な解が得られるとされる。
この設計は、Deep Signalで以前取り上げたHyperAgents論文でMetaが示した「タスクエージェントとメタエージェントの分離」という思想と連続している。HyperAgentsが「改善メカニズム自体を書き換えるメタエージェント」を提案したのに対し、Muse Sparkでは実際の推論タスクを特化エージェントに並列分散させる形でその応用が見える。エージェント間の協調コストが実際の応答レイテンシーにどう影響するかは、本番での測定データが公開されるまで判断が難しい。
GPT-5.4・Gemini 3.1との位置づけ——マルチモーダル設計の分岐点
2026年前半のマルチモーダルLLM市場では、Muse Spark以外に主要な競合としてOpenAIのGPT-5.4とGoogleのGemini 3.1がある。3者のアーキテクチャ設計には明確な差異がある。
GPT-5.4は、テキストLLMの基盤にビジョンエンコーダを後付けする従来型アーキテクチャを洗練したモデルだ。Computer Useによるデスクトップ操作統合が特徴で、モデル自体の革新よりも「LLMを行動エージェントとして使う」インターフェース層の充実に注力している。Muse SparkのUMTのような表現空間レベルの統一は行っておらず、アーキテクチャの修正より実用性の拡張を優先した判断が見える。
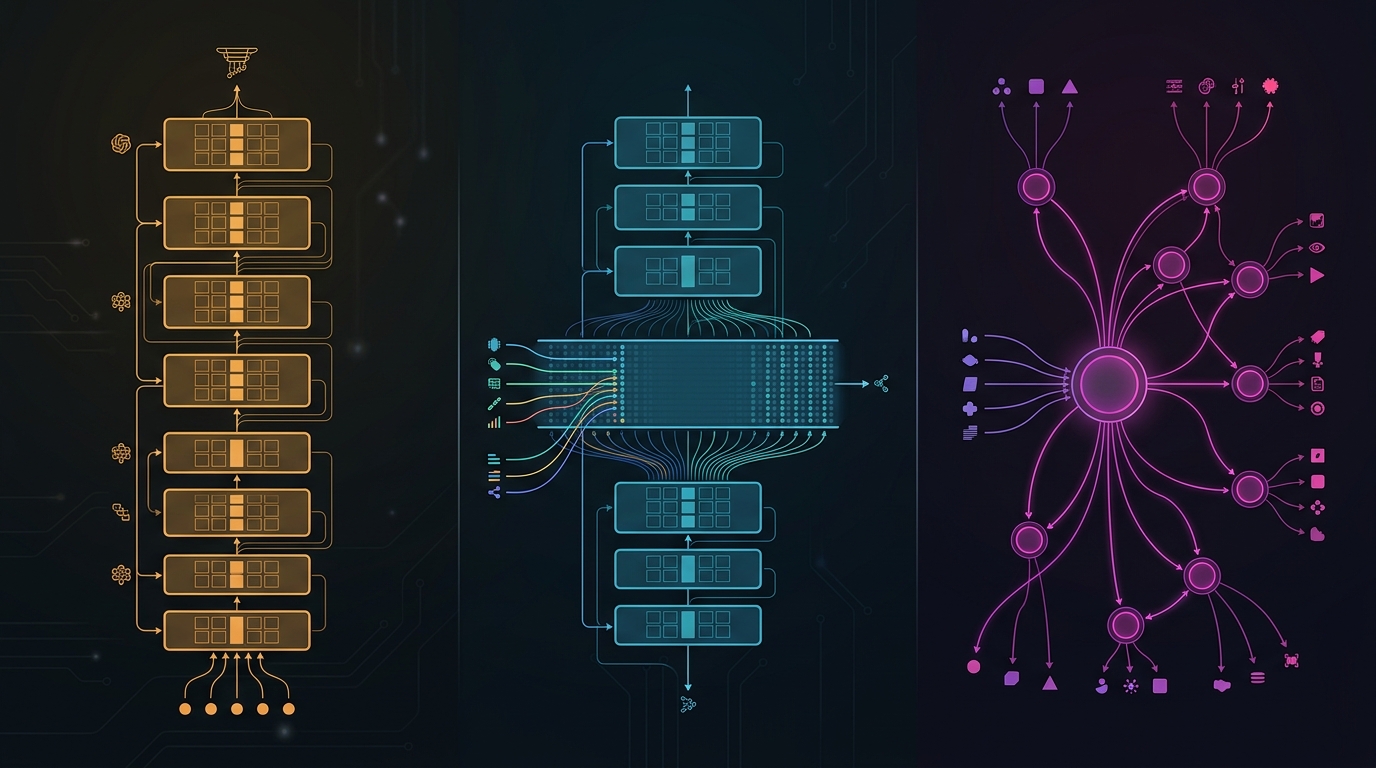
Gemini 3.1はMuse Sparkと設計上最も近い方向性を持つ。ネイティブマルチモーダル——テキスト・画像・音声・動画を単一モデルで統合的に処理するという思想は共通しており、競合関係が直接的だ。差異としては、Gemini 3.1がロングコンテキスト処理(最大200万トークン)を設計の中心に置いているのに対し、Muse Sparkは思考圧縮による効率化を優先している点が挙げられる。長文書の理解よりも、短いが複雑なマルチモーダルクエリの精度を重視する設計判断だ。
デプロイ戦略も3者で異なる。GPT-5.4はAPIと自社製品の両方で展開し、Gemini 3.1はGoogleサービス全体に統合されている。Muse SparkはMeta AI・WhatsApp・Instagramというソーシャルプラットフォームへの統合が主軸だ。モデル性能の比較より、どの「生活圏」にいるユーザーにリーチするかという展開戦略の差が、実際のユーザー数に最も大きく影響するかもしれない。
HIVEとの対比——マルチモーダル推論を外から強化するか内から設計するか
Muse Sparkのアーキテクチャを整理したとき、別の視角から考えるのに有益なのがHIVEフレームワークとの対比だ。HIVEはMM-BRIGHTベンチマークで+14.1ポイントの改善を示したが、それはモデルアーキテクチャへの変更ではなく、LLMを「仮説を立て検証するパイプライン」として使うフレームワーク設計による改善だった。
HIVEが示したのは「既存のLLMをインテリジェントに組み合わせればマルチモーダル推論の精度は大幅に上がる」という知見だ。Muse SparkはUMT・CMAFというアーキテクチャレベルの変更でこれを達成しようとしている。「推論の改善をモデル内部で行うか、モデルの外側のフレームワークで行うか」という設計の二極化として捉えると整理しやすい。
実際の展開においては、両者は競合ではなく補完的に機能する可能性が高い。Muse Sparkのようなネイティブマルチモーダルモデルを基盤として、HIVEのような推論強化フレームワークで包む構成は、将来的なRAGシステム設計で標準的なパターンになりうる。2026年4月時点でのMuse Sparkに関する技術的な詳細(アーキテクチャの実装仕様・ベンチマーク結果の完全版)は学術論文形式では未公開であり、現時点では公開情報から読み取れる設計の方向性を記述するにとどまる。


