
Googleは2026年3月26日、「Gemini 3.1 Flash Live」をGoogle AI Studio上のLive APIで開発者プレビュー公開した。このモデルはリアルタイムの音声・映像処理を専門に設計されており、90以上の言語での低レイテンシ会話、背景ノイズへの耐性、複数ステップのツール呼び出し(ComplexFuncBench Audioで90.8%)を実現する。本記事ではモデルの技術的特徴と、実際に音声AIエージェントを構築するためのアーキテクチャパターンを解説する。
Gemini 3.1 Flash Liveの技術的特徴
最大の特徴は「ネイティブ音声処理」だ。従来の音声AIシステムは「音声→文字起こし(ASR)→LLM→テキスト→音声合成(TTS)」という直列パイプラインで処理していた。これはレイテンシが積み重なりやすく、会話の自然なタイミング(相槌、割り込み、間)を再現しにくかった。Gemini 3.1 Flash LiveはASRとTTSを内部化し、音響的なニュアンス(声のトーン、スピード、感情)を直接処理する。

ノイズ耐性も大幅に向上した。交通騒音やテレビの音が混じった環境でも、会話の音声を高精度に抽出できる。カスタマーサポート、コールセンター自動化、フィールド作業支援など、騒がしい環境での使用が想定されるユースケースに特に有効だ。多言語対応は90言語以上で、日本語も含まれる。
APIの基本——WebSocketでの双方向通信
Gemini 3.1 Flash LiveはWebSocket(WSS)による全二重通信を採用している。これにより、ユーザーが話しながらモデルが応答を開始する「Barge-in(割り込み)」が自然に実現できる。APIモデルIDは `gemini-3.1-flash-live-preview` で、Google AI StudioのLive APIから利用可能だ。

基本的な接続フローはシンプルだ。まずWebSocket接続を確立し、セッション設定(モデルID、ツール定義、言語設定等)を送信する。その後、音声フレームをリアルタイムでストリーミング送信し、モデルからの音声応答や関数呼び出し結果をストリーミング受信する。従来のHTTP RESTful APIとは大きくパラダイムが異なるため、イベントループの設計が重要になる。
ツール呼び出し(Function Calling)もリアルタイムセッション内でサポートされており、会話の流れの中でAPIを叩いたりデータベースを参照したりする「行動しながら話す」エージェントが構築できる。ツール定義は通常のGemini APIと同じJSON Schema形式で指定する。
音声エージェントのアーキテクチャパターン
実際のプロダクションシステムでは、Gemini 3.1 Flash Liveを中心に据えつつ、いくつかのサポートコンポーネントを組み合わせるのが一般的だ。まず「セッション管理レイヤー」が必要だ。WebSocket接続はセッション固有であり、ユーザーが一時的に接続を切断した場合のリカバリー、長時間接続での接続維持(Keep-Alive)、並行セッション数の管理などを担う。
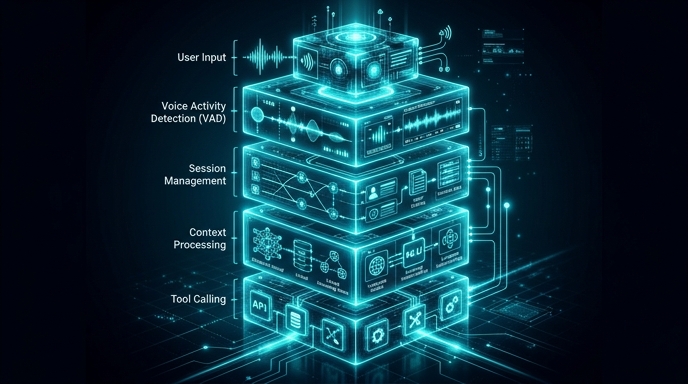
次に「コンテキスト管理」が重要になる。音声会話はテキストチャットと異なり、会話ターンの区切りが明確ではない。「ユーザーが話し終えたタイミング」を検出し、どこまでが現在のターンかを判断するVAD(Voice Activity Detection)ロジックが必要だ。Gemini 3.1 Flash Liveは内部でVADを持つが、アプリケーション側でも会話コンテキストの蓄積と要約を管理すると長時間セッションの品質が安定する。
カスタマーサポート自動化への応用
最も需要が高いユースケースはカスタマーサポートの音声自動化だ。従来のIVR(自動音声応答)は事前定義のスクリプトに縛られていたが、Gemini 3.1 Flash Liveを使えば自然言語で柔軟に会話しながら、バックエンドAPIを呼び出して注文確認・返品処理・在庫照会などを自律的に実行できる。

特に日本語対応は重要で、敬語・丁寧語・ビジネス語のコンテキストに合わせた応答生成が求められる。Gemini 3.1 Flash Liveは90言語に対応しており、日本語の音声認識精度も前世代モデルから向上している。コールセンターの一次対応自動化、予約変更・取り消しの自動処理、FAQ応答などに実用的に使えるレベルに達してきた。
開発時の注意点として、音声AIエージェントの品質評価はテキストベースのLLMより難しい。音声認識精度、応答のタイミング、イントネーションの自然さ、ノイズ耐性など多角的な評価が必要だ。プロダクション前には実際の使用環境を模したストレステストを行い、想定外の発話パターンへの対応を確認することが推奨される。
音声AIスタックが揃う
Gemini 3.1 Flash Liveが示す「ネイティブ統合型音声処理」の登場は、音声AIエコシステム全体の変容を読み解く文脈で捉えるべきだ。Deep Signalが報じたCohereのオープンソース音声認識モデルはASR(音声→テキスト)の「入力側」をオープンソース化し、データプライバシー重視の金融・医療機関がオンプレミスで文字起こし基盤を持てるようにした。Mistral AIの音声生成モデルはTTS(テキスト→音声)の「出力側」をオープンソース化し、ElevenLabsやOpenAIが先行する音声合成市場にOSS代替をもたらした。Gemini 3.1 Flash Liveはその両側を内部化した統合モデルとして位置づけられる——三者を並べると、音声AIスタックの入力・処理・出力が2026年3月に同時期に揃ったことが見えてくる。
Apple SiriへのGPT-4o以外のAI接続方針(Deep Signal既報)も、この文脈で重要な意味を持つ。Appleがモジュール型の音声スタックを整備することで、GoogleのGeminiやCohereのASRが「Siriの中身」として採用される可能性が現実になる。Gemini 3.1 Flash Liveのような統合モデルと、CohereやMistralのような専門特化OSS——どちらが企業の音声エージェント基盤として主流になるかは、プライバシー要件とパフォーマンス要件のトレードオフで決まる。エンタープライズ市場では「統合型の利便性」と「コンポーネント型の制御性」の競争が今後数年続くだろう。


